1Learning Outcomes¶
Consider how to reduce the miss rate and miss penalty components of the average memory access time formula.
Consider tradeoffs with cache optimizations: block size, cache size, associativity, and multilevel caches.
🎥 Lecture Video
The average memory access time formula gives us a framework to present cache optimizations for improving cache performance:
We can organize basic cache optimizations into how it impacts each of the three terms in this equation:
Reducing the miss rate
Reducing the miss penalty
Reducing the hit time
The cache optimization techniques in this chapter improve performance in one of the above categories, but often come at the cost of hurting other categories. Table 1 summaries the complexity and performance benefits.
Table 1:Adaptation of Figure B.18 from Computer Organization: A Quantitative Approach. Summary of basic cache optimizations showing impact on cache performance and complexity. Generally a technique helps only one factor. (+) means the technique improves the factor (reduces miss rate, hit time, or miss penalty), (-) means it hurts that factor, and blank means it has no impact.
| Technique | Hit Time | Miss Penalty | Miss rate |
|---|---|---|---|
| Larger block size | – | + | |
| Larger cache size | – | + | |
| Higher associativity | – | + | |
| Multilevel caches | + | ||
| Avoiding address translation during cache indexing[1] | + |
We first note that of the cache design policies, the replacement policy and write policy are not considered common cache optimizations. Rather, in practice caches are almost always designed with LRU (or FIFO) and write-back policies; the other alternatives are not considered reasonable. We thus focus our discussion in this section on other design principles and cache size/capacity.
2Larger Block Size¶
Larger blocks take advantage of spatial locality and so will reduce compulsory misses. At the same time, larger blocks may be costly for a few reasons, as shown in Figure 1:
Miss penalty: With larger blocks, there is more to read from memory on a compulsory miss (and write to memory upon replacement). Larger blocks will increase the miss penalty.
Miss rate: Initially, larger blocks will reduce miss rate because they improve spatial locality. Larger blocks reduce the number of blocks in the cache, so larger blocks may increase conflict misses and even capacity misses if the cache is small. Put another way, having fewer blocks can compromise temporal locality and (at some inflection point) increase the miss rate.
AMAT: Because AMAT incorporates both of these components, increasing the block size past a certain point can increase AMAT.
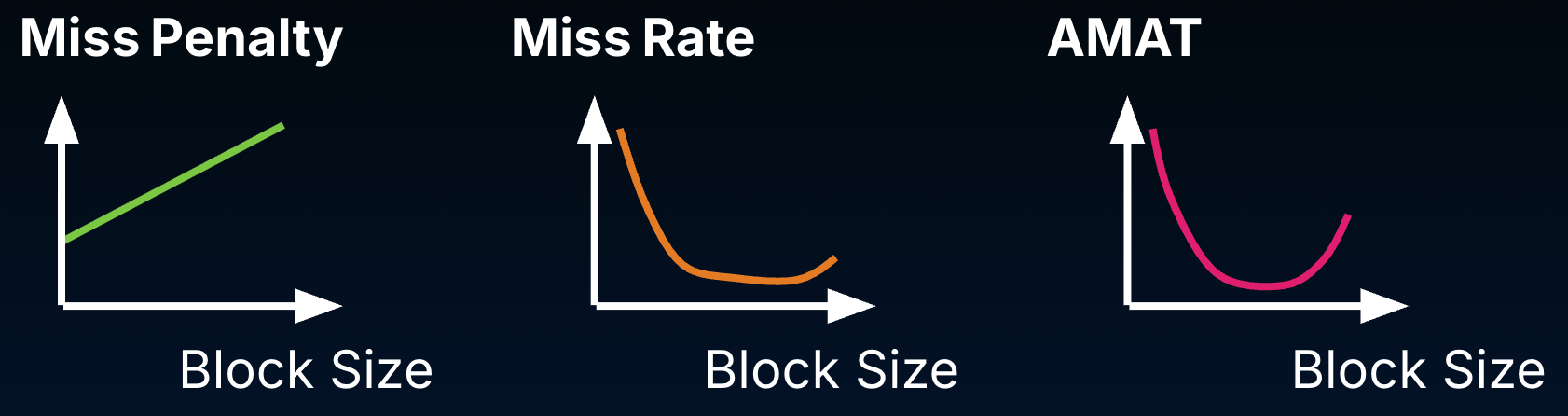
Figure 1:While larger blocks can initially reduce miss rate because they improve spatial locality, they also reduce the number of blocks in the cache and can compromise temporal locality. Past a certain point, average memory access time will increase with larger block size.
Figure 2 shows the miss rate tradeoff in more detail, as measured on an early 2000s benchmark.
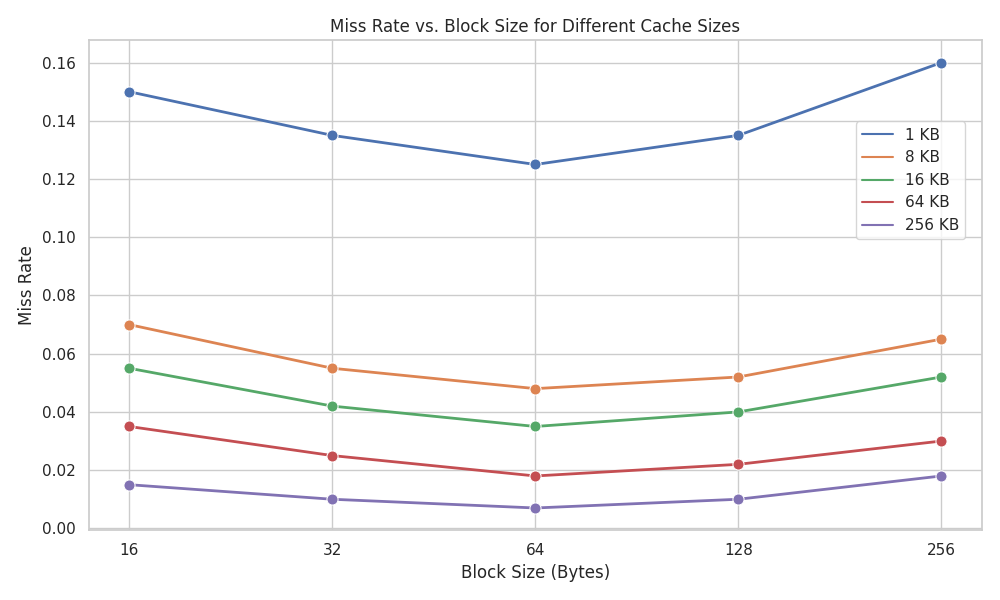
Figure 2:Miss rate versus block size for four different caches. Note that miss rate actually goes up if the block size is too large relative to the cache size. Adjusted version of Figure B.10 from _Computer Organization: A Quantitative Approach.
3Larger Cache Size¶
From Computer Organization: A Quantitative Approach, Appendix B.3:
The obvious way to reduce capacity misses in Figure 3 is to increase capacity of the cache. The obvious drawback is potentially longer hit time and higher cost and power. This technique has been especially popular in off-chip caches.
In Figure 3, we see that as cache size increases, miss rate decreases for all cache associativities.
As a modern example, the M1 chip has an L2 cache sized to 12 MiB—significantly larger than its L1 cache with 128 KiB.[2]
4Higher Associativity¶
As discussed earlier, higher associativity reduces the miss rate by reducing compulsory misses.
Computer Organization: A Quantitative Approach measures miss rate on caches of different sizes and different associativities, as shown in Figure 3. The direct-mapped cache (1-way set associative) has the highest miss rate across cache sizes.
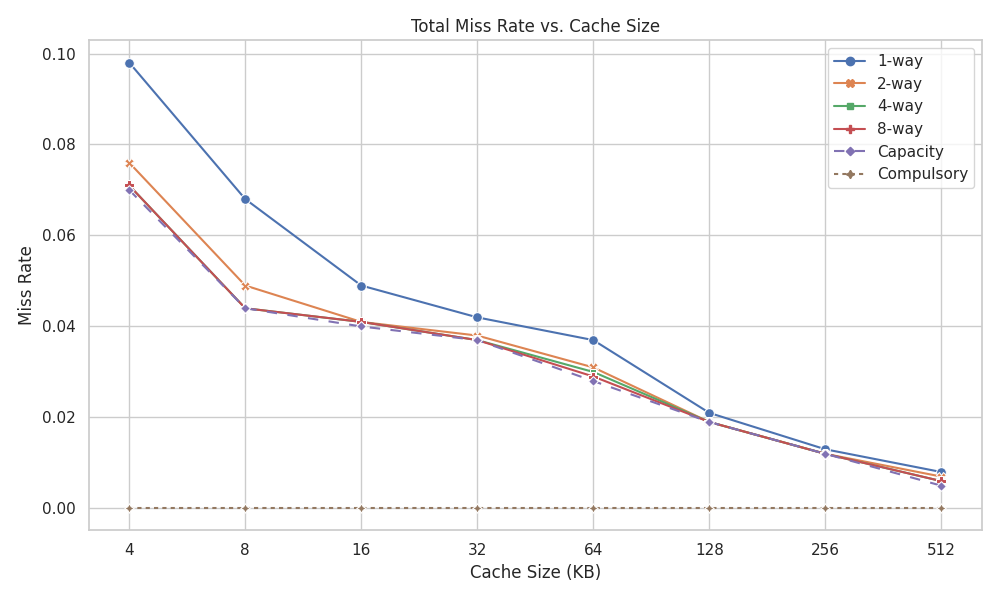
Figure 3:Total miss rate for each size cache, by associativity. Note that together, compulsory misses and capacity misses (dashed lines) are by definition the miss rate of a fully associative cache. Adjusted version of Figure B.9 from Computer Organization: A Quantitative Approach.
Also as discussed earlier, fully associative caches complicate hardware and can therefore increase hit time. Nevertheless, in modern processors, L1 caches have reasonable associativity, e.g., 4-way or 8-way.[3] [2]
5Multilevel Caches¶
We note that implementing multilevel caches costs hardware space (see an earlier section of the cache space on the Apple A14 Bionic Chip. When we introduced key cache terminology, we also noted in a footnote that the Apple M1 chip has differently sized blocks for the L1 cache and L2 cache. This also complicates hardware. Nevertheless, multilevel caches are widely used in modern processors that handle a wide variety of applications.
6Other techniques¶
Other techniques certainly exist but are beyond the scope of this course–or at least, our coverage of the topic at present. Two additional techniques are addressed in _Computer Organization: A Quantitative Approach, B.3":
Avoiding address translation when indexing the cache. We discuss this later[1] when we introduce virtual memory. This approach reduces hit time and is widely used.
(out of scope) Giving read misses priority over writes. If a read miss occurs that would also cause a memory write (i.e., a dirty block must be written back to the cache), implement a write buffer. This way, on a read miss, copy the dirty block to a write buffer, then read memory, then write memory from the buffer.
Yu et al. (SEC 2023) Table 1 reports that the Apple M1 chip P(erformance)-core has has an 8-way, 128-KiB (64B blocks, 256 sets) L1 data cache and 12-way, 12-MiB (128B blocks, 8192 sets) 16-way L2 caches. presentation, paper.
I don’t have an exact source for this, but here are some snippets: Computer Organization: A Quantitative Approach says, “In many recent processors, designers have opted for more associativity rather than larger caches” (Section 2.2). The section further mentions that the ARM Cortex-A8 (2005) uses four-way set associative caches.