1Learning Outcomes¶
Write programs that leverage understanding of the underlying cache design.
Define cache blocking.
We have seen in a previous section how as computer architects, we can reduce cache misses by increasing the capacity of our cache. However, as programmers, we often may not have control over the hardware of our computer. It is not trivial to swap out the cache. Instead, we must assume that we have some fixed hardware architecture, then see how we can rewrite our programmer to maximize use of the hardware.
Cache blocking is a programmer technique that rearranges data accesses to make better use of the data brought into the cache and reduce cache misses.
In this section, we consider one specific program benchmark: matrix multiplication. After trying an initial naive implementatno, we hhow knowing the underlying design of our cache can actually improve how we write programs.
2Matrix Multiplication (DGEMM)¶
In this section, we use a matrix multiplication benchmark. In this example, we will consider multiplying matrix (4 rows 8 columns) by matrix (8 rows 4 columns) to produce the matrix (4 rows 4 columns).[1]
Assume that matrices , , and are stored in row-major order as int A[], int B[], and int C[].
C code, for your reference:
3Architecture details¶
Suppose we run our C program on a 32-bit architecture that has a single-layer cache:
128B capacity
fully associative
16B block size (so 8 blocks)
LRU replacement policy
Write-back write policy with dirty bit
For our matrix multiplication example, we will assume that on this architecture, sizeof(int) is 4, so each block holds four ints.
4Approach 1: Naive DGEMM Memory Access Pattern¶
Assume the cache starts out cold.
Suppose we first compute , which is the dot-product of the (zero-indexed) zero-th row of and the (zero-indexed) zero-th column of .
Figure 1:Computing as vector multiplication of the zero-th row of and the zero-th column of . Use the menu bar to trace through the animation or access the original Google Slides.
Show cache hits/misses
Assume sum is stored in a register. Assume accessing any element of A, B, or C will result in a memory access.
A[0][0] * B[0][0]. Compulsory cache miss onA[0][0], compulsory cache miss onB[0][0].Cache contents, in order of most recently used:
Row 0 of B
Row 0 of A, first half (elements 0 to 3)
A[0][1] * B[1][0]. Cache hit onA[0][1], compulsory cache miss onB[1][0].Cache contents:
Row 1 of B
Row 0 of A, first half
Row 0 of B
A[0][2] * B[2][0]. Cache hit onA[0][2], compulsory cache miss onB[2][0].Cache contents:
Row 2 of B
Row 0 of A, first half
Row 1 of B
Row 0 of B
A[0][3] * B[3][0]. Cache hit onA[0][3], compulsory cache miss onB[3][0].Cache contents:
Row 3 of B
Row 0 of A, first half
Row 2 of B
Row 1 of B
Row 0 of B
A[0][4] * B[4][0]. Compulsory cache miss onA[0][4], compulsory cache miss onB[4][0].Cache contents:
Row 4 of B
Row 0 of A, second half
Row 3 of B
Row 0 of A, first half
Row 2 of B
Row 1 of B
Row 0 of B
A[0][5] * B[5][0]. Cache hit onA[0][5], compulsory cache miss onB[5][0].Cache contents:
Row 5 of B
Row 0 of A, second half
Row 4 of B
Row 3 of B
Row 0 of A, first half
Row 2 of B
Row 1 of B
Row 0 of B
Cache is now at capacity (full).
A[0][6] * B[6][0]. Cache hit onA[0][6], compulsory cache miss onB[6][0]. Cache is full, so replace least recently used block (row 0 of B).Cache contents:
Row 6 of B
Row 0 of A, second half
Row 5 of B
Row 4 of B
Row 3 of B
Row 0 of A, first half
Row 2 of B
Row 1 of B
Row 0 of B
A[0][7] * B[7][0]. Cache hit onA[0][6], compulsory cache miss onB[7][0]. Cache is full, so replace least recently used block (row 1 of B).Cache contents:
Row 7 of B
Row 0 of A, second half
Row 6 of B
Row 5 of B
Row 4 of B
Row 3 of B
Row 0 of A, first half
Row 2 of B
Row 1 of B
C[0][0] = sum. Cache miss onC[0][0]. Cache is full, so replace least recently used block (row 2 of B).Cache contents:
Row 0 of C
Row 7 of B
Row 0 of A, second half
Row 6 of B
Row 5 of B
Row 4 of B
Row 0 of A, first half
Row 3 of B
Cache contents after computing , in order of most recently used:
Row 0 of C
Row 7 of B
Row 0 of A, second half
Row 6 of B
Row 5 of B
Row 4 of B
Row 0 of A, first half
Row 3 of B
Next, suppose we computed , which is the dot-product of the (zero-indexed) zero-th row of and the (zero-indexed) first column of .
Figure 2:Computing as vector multiplication of the i-th row of and the j-th column of . Use the menu bar to trace through the animation or access the original Google slides.
Show cache hits/misses
Assume sum is stored in a register. Assume accessing any element of A, B, or C will result in a memory access.
A[0][0] * B[1][0]. Cache hit onA[0][0], non-compulsory cache miss onB[1][0]. Cache is full, so replace least recently used block (row 3 of B).Cache contents:
Row 0 of B
Row 0 of A, first half
Row 0 of C
Row 7 of B
Row 0 of A, second half
Row 6 of B
Row 5 of B
Row 4 of B
A[0][1] * B[1][1]. Cache hit onA[0][1], non-compulsory cache miss onB[1][1]. Cache is full, so replace least recently used block (row 4 of B).Cache contents:
Row 1 of B
Row 0 of A, first half
Row 0 of B
Row 0 of C
Row 7 of B
Row 0 of A, second half
Row 6 of B
Row 5 of B
A[0][2] * B[1][2]. Cache hit onA[0][2], non-compulsory cache miss onB[1][2]. Cache is full, so replace least recently used block (row 5 of B).Cache contents:
Row 2 of B
Row 0 of A, first half
Row 1 of B
Row 0 of B
Row 0 of C
Row 7 of B
Row 0 of A, second half
Row 6 of B
A[0][3] * B[1][3]. Cache hit onA[0][3], non-compulsory cache miss onB[1][3]. Cache is full, so replace least recently used block (row 6 of B).Cache contents:
Row 3 of B
Row 0 of A, first half
Row 2 of B
Row 1 of B
Row 0 of B
Row 0 of C
Row 7 of B
Row 0 of A, second half
A[0][4] * B[1][4]. Cache hit onA[0][4], non-compulsory cache miss onB[1][4]. Cache is full, so replace least recently used block (row 7 of B).Cache contents:
Row 4 of B
Row 0 of A, second half
Row 3 of B
Row 0 of A, first half
Row 2 of B
Row 1 of B
Row 0 of B
Row 0 of C
A[0][5] * B[1][5]. Cache hit onA[0][5], non-compulsory cache miss onB[1][5]. Cache is full, so replace least recently used block (row 0 of C).Cache contents:
Row 5 of B
Row 0 of A, second half
Row 4 of B
Row 3 of B
Row 0 of A, first half
Row 2 of B
Row 1 of B
Row 0 of B
A[0][6] * B[1][6]. Cache hit onA[0][6], non-compulsory cache miss onB[1][6]. Cache is full, so replace least recently used block (row 0 of B).Cache contents:
Row 6 of B
Row 0 of A, second half
Row 5 of B
Row 4 of B
Row 3 of B
Row 0 of A, first half
Row 2 of B
Row 1 of B
A[0][7] * B[1][7]. Cache hit onA[0][7], non-compulsory cache miss onB[1][7]. Cache is full, so replace least recently used block (row 1 of B).Cache contents:
Row 7 of B
Row 0 of A, second half
Row 6 of B
Row 5 of B
Row 4 of B
Row 3 of B
Row 0 of A, first half
Row 2 of B
C[0][0] = sum. Non-compulsory cache miss onC[0][0]. Cache is full, so replace least recently used block (row 2 of B).Cache contents:
Row 0 of C
Row 7 of B
Row 0 of A, second half
Row 6 of B
Row 5 of B
Row 4 of B
Row 3 of B
Row 0 of A, first half
Cache contents after computing , in order of most recently used:
Row 0 of C
Row 7 of B
Row 0 of A, second half
Row 6 of B
Row 5 of B
Row 4 of B
Row 3 of B
Row 0 of A, first half
In our matmul example, we know that B is stored in row-major-layout. To access a column of as is needed in matrix multiplication, we must load in all 8 rows of B.
From P&H 4.4 for square matrices (N-by-N):
If the cache can hold one N-by-N matrix and one row of N, then at least the
ith row ofAand the entire matrixBmay stay in the cache. Less than that and misses may occur for bothBandC. In the worst case, there would be 2 N3+ N2 memory words accesed for N3 operations.
5Approach 2: Cache Blocking with Transpose¶
One observation is that it would be much better to load in just the 8 elements in the column of B, and not elements in other columns needed for later matrix multiplications.
A cache blocking technique could transpose B before matrix multiplication. The transpose of is written as and is defined where for all indices and , as shown in Figure 3.
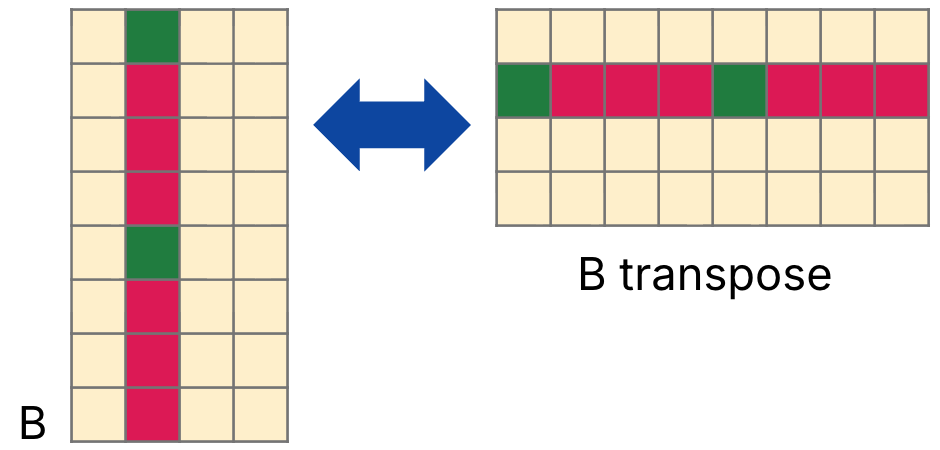
Figure 3: is the matrix transpose of
If we maintain a copy of B_T (mathematically ), we can therefore redefine our matrix multiplication as follows:
// cache-blocking code
// for row i, col j of C
int sum = 0; // sizeof(int) = 4
for (int k = 0; k < size; k++) {
sum += A[i][k] * B_T[j][k];
}
C[i][j] = sum;Notes:
B_Tis still a matrix stored in row-major order. However, now our original matrix is effectively stored in column-major order.With the above optimization, we prevent repeatedly replacing and fetching the same data from main memory. Instead, we load in each column of
B, two memory accesses at a time.
Transposing is quite slow; it also requires a N2 overhead to complete and triggers the same types of cache misses as we observed in our original computation. We have simply moved our poor cache performance from matrix multiplication to another part of the program.
6Approach 3: Cache Blocking with Submatrix Computation (Tiling)¶
Our second cache blocking approach observes that matrix multiplication can be computed piecewise. A submatrix (i.e., tile) of can be computed as the sum of multiplying different submatrices of and .
Figure 4 illustrates cache blocking with a blocking factor or BLOCKSIZE of 2. We compute the 2x2 tile of with elements , where and . This tile can be computed as four submatrix multiplications.
Figure 4:Cache blocking. Use the menu bar to trace through the animation or access the original Google slides.
Show Explanation
Multiply the first two elements in Rows 0 and 1 of A by the first two elements in Rows 0 and 1 of B. Store the four results in the target C tile.
Cache contents[2]:
Row 0 of A, first half
Row 1 of A, first half
Row 0 of B
Row 1 of B
Row 0 of C
Row 1 of C
Multiply the next two elements of A by the first two elements in Rows 2 and 3 of B. Add to the results in the target C tile.
Cache contents[2]:
Row 0 of A, first half
Row 1 of A, first half
Row 0 of B
Row 1 of B
Row 0 of C
Row 1 of C
Row 2 of B
Row 3 of B
Multiply the next two elements of A by the first two elements in Rows 4 and 5 of B. Add to the results in the target C tile.
Cache contents[2]:
Row 3 of A, first half
Row 4 of A, first half
Row 0 of C
Row 1 of C
Row 4 of B
Row 5 of B
Multiply the last two elements of A by the first two elements in Rows 6 and 7 of B. Add to the results in the target C tile.
Cache contents[2]:
Row 3 of A, first half
Row 4 of A, first half
Row 0 of C
Row 1 of C
Row 6 of B
Row 7 of B
7Performance Analysis¶
See the following two sections:
Approach 1: Naive DGEMM
Approach 2: DGEMM Transpose
Approach 3: DGEMM Tiled (with SIMD)
A tiled approach to matrix multiplication is much more efficient when we can leverage parallelism in hardware.
8Summary: Cache Blocking¶
Note that cache blocking may still replace rows of that will be needed later; it does not avoid all capacity misses. However, it reduces the total number of memory accesses, thereby reducing the total number of compulsory misses.
From P&H 4.4 for square matrices (N-by-N):
Looking only at capacity misses, the total number of memory words accessed is 2 N3/
BLOCKSIZE+ N2. This total is an improvement by about a factor ofBLOCKSIZE.
Blocking exploits a combination of spatial and temporal locality:
benefits from spatial locality
benefits from temporal locality
benefits from spatial locality (more results of are computed for the same memory accesses to and ).