1Learning Outcomes¶
Explain the DGEMM benchmark: row-major order matrix multiplication.
Explain why C DGEMM runs faster than Python DGEMM.
Understand that in practice, library implementations like NumPy DGEMM are plenty fast because they use the optimizations described in this chapter.
🎥 Lecture Video
🎥 Lecture Video
How might we begin evaluating performance? Remember from our discussion of the iron law of processor performance that in order to evaluate performance, we must determine a program benchmark. Over the next few lectures, we will evaluate different optimizations of a core benchmark to many engineering, data, and image processing tasks today: matrix multiplication.
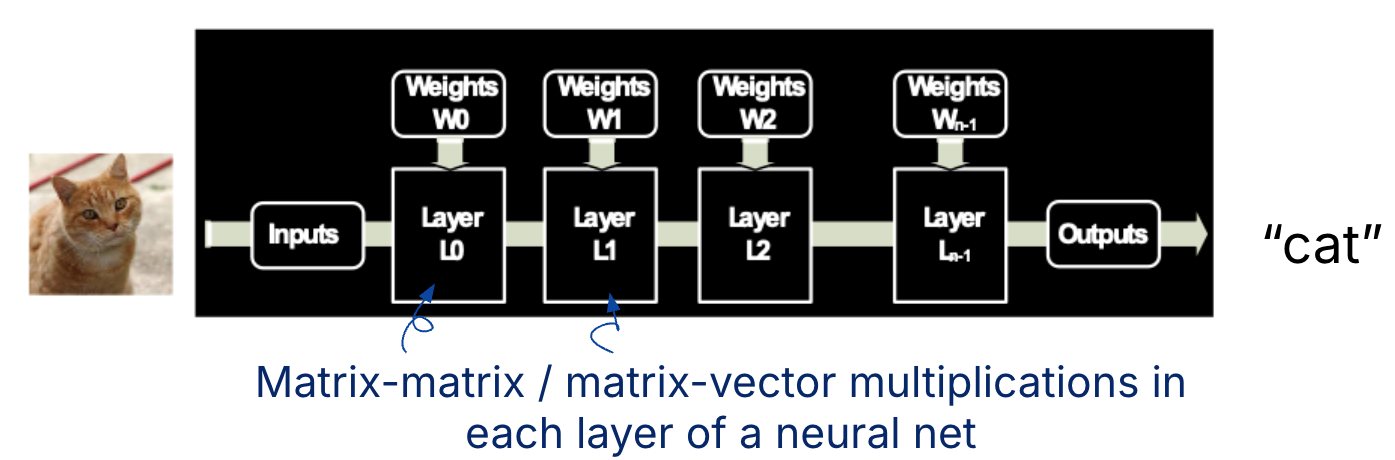
Figure 1:A machine learning application is shown. There are many matrix-matrix and matrix-vector multiplications, e.g., in each layer of a multi-layer neural network. Matrix multiplication is also core to tasks in other domains, e.g., image filtering and noise reduction.
2Matrix Multiplication¶
Matrix multiplication is defined as for matrices , , and . If is the set of all real numbers, the dimensions of these three matrices are: .
To compute each element of the resulting matrix , we take the dot product of a row of and a column of . The dot product of two vectors is the sum of the element-wise product of the two vectors. Figure 2 shows how we can compute the zero-th row, zero-th column element of , , by multiplying element-wise the (zero-indexed) zero-th row of and zero-th column of , then summing everything together.
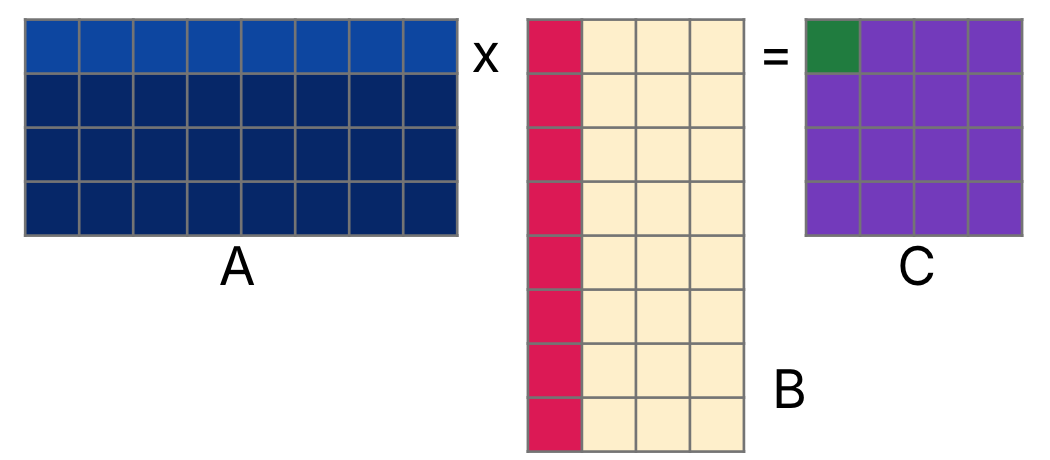
Figure 2:Compute by taking the dot product of row 0 of and column 0 of .
Similarly, to compute , we can multiply element-wise the zero-th row of and first column of , then sum everything together, as in Figure 3.
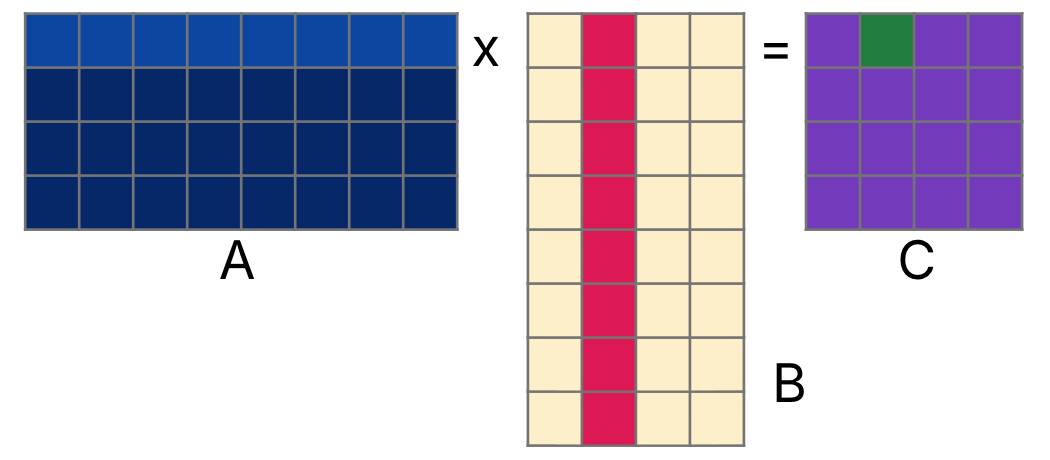
Figure 3:Compute by taking the dot product of row of and column of .
// basic matrix multiplication
void dgemm(int N, double **A, double **B, double **C) {
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
// for row i, col j of C
double sum = 0;
for (int k = 0; k < size; k++) {
sum += A[i][k] * B[k][j];
}
C[i][j] = sum;
}
}
}The code above assumes that matrices are stored as two-dimensional arrays, but this will complicate our analysis of memory—particularly as it relates to spatial locality for caches and the memory hierarchy. We therefore describe the row-major order implementation below, which we will use as our benchmark task.
3The DGEMM Code Benchmark¶
The above matrix multiplication task is common called DGEMM, which stands for Double-precision GEneral Matrix Multiply.
The following code represents matrices , , and as variables A, B, and C, respectively. Further assumptions:
Heap allocated;
Square with dimensions ; and
Have elements stored in a
doublearray, in row-major order.
DGEMM: Double-precision General Matrix Multiplication
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15matrix_d_t *dgemm(matrix_d_t *A, matrix_d_t *B) { if (A->ncols != B->nrows) return NULL; matrix_d_t *C = init_mat_d(A->nrows, B->ncols); for (int i = 0; i < A->nrows; i++) { for (int j = 0; j < B->ncols; j++) { double sum = 0; for (int k = 0; k < A->ncols; k++) { sum += A->data[i*A->ncols+k]*B->data[k*B->ncols+j]; } C->data[i*C->ncols+j] = sum; } } return C; }
Figure 4 shows the innermost loop of the DGEMM code to compute , where .
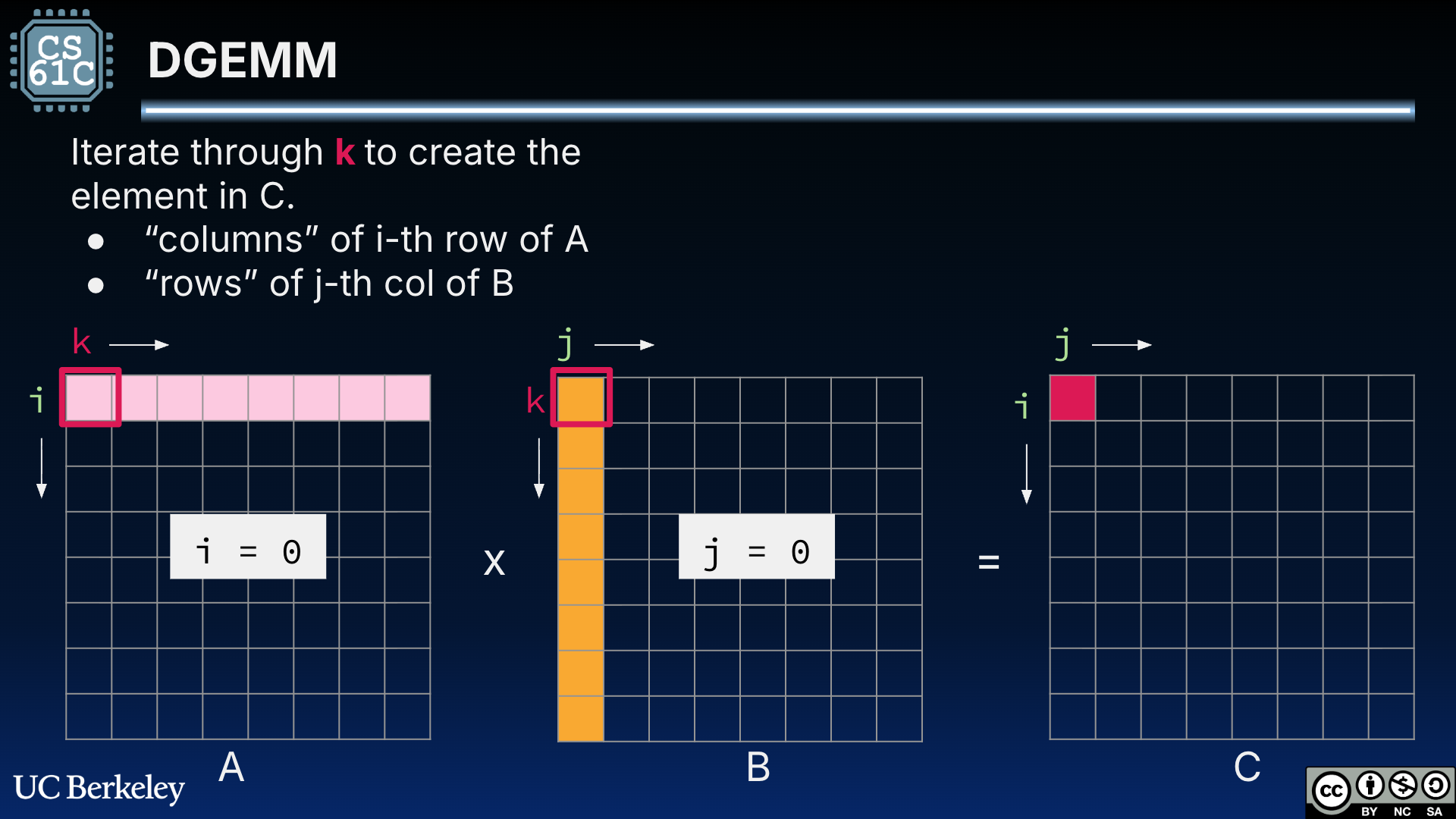
Figure 4:DGEMM for square matrices A and B. is computed as the dot product of row i = 0 of A and column j = 0 of B.
3.1Matrix Dimensions¶
The P&H textbook assumes that all matrices are square, where N specifies both row and column dimensions. For those less familiar with matrix multiplication, reducing to this one value may make it hard to picture matrix multiplication, even if it makes our code simpler.
For the purposes of our course demo, we will assume DGEMM works on a struct that stores the row and column dimensions along with our matrix data. as shown below. All matrices are pointers to heap-allocated structs; these are allocated and freed with init_mat_d and free_mat_d.
DGEMM Helpers
1 2 3 4 5 6 7 8 9 10typedef struct { int nrows; int ncols; double* data; } matrix_d_t; matrix_d_t *init_mat_d(int nrows, int ncols); matrix_d_t *load_mat_d(FILE* f); void print_mat_d(matrix_d_t *mat); void free_mat_d(matrix_d_t *mat);
Matrix multiplication dimensions with the matrix_d_t struct.
| Matrix | C declaration | Rows | Columns |
|---|---|---|---|
matrix_d_t *A; | A->nrows or | A->ncols or | |
matrix_d_t *B; | B->nrows or | B->ncols or | |
matrix_d_t *C; | C->nrows or | C->ncols or |
Going forward, we will use this syntax, but all of our timing benchmarks and subsequent optimizations will assume that all matrices are square, i.e., . We will further assume powers of two (or at minimum a multiple of 4). We will test:
etc.
In practice, matrix dimensions are passed as parameters to avoid structs and keep indirection to a minimum. We will probably revisit and rewrite this benchmark in future semesters to measure performance more clearly.
3.2Row-major order¶
Assume that matrices , , and are stored as A, B, and C. In the code, these matrices are stoerd as arrays of double arrays. By convention, these arrays store matrix elements in row-major order.[1]
In Figure 5, each element of A[i] is the -th row of matrix ; furthermore, the zero-th element of the -th row immediately follows the last element of the -th row, as shown in Figure 5.
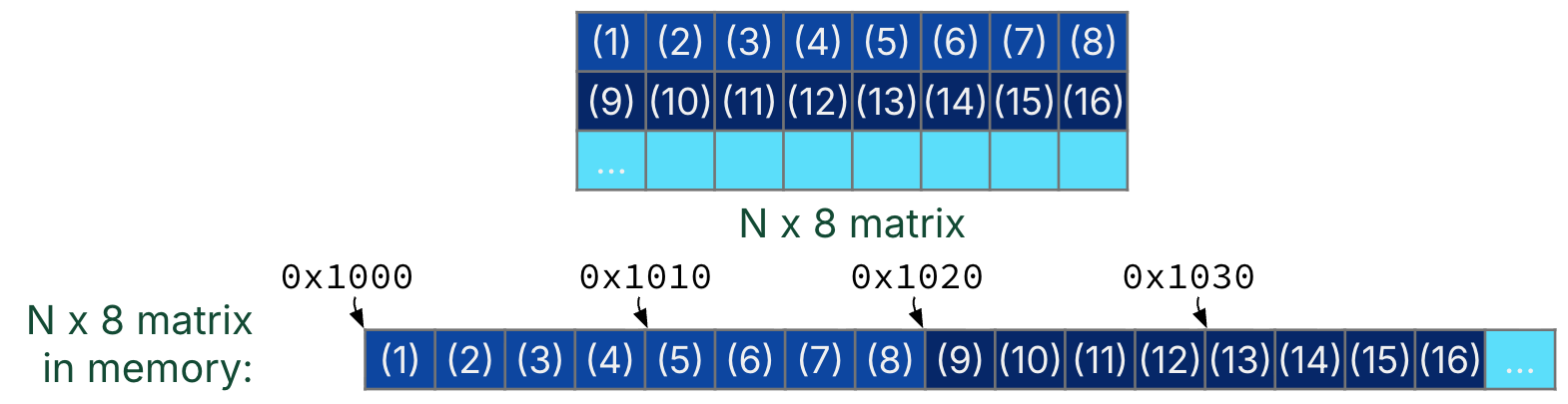
Figure 5:Assume that all matrices are stored in row-major order.
We revisit the inner loop of the DGEMM benchmark code. Flip between the two tabs to see how to compute , the element of in row i and column j if we assume all matrices are stored in row-major order.
double sum = 0;
for (int k = 0; k < A->ncols; k++) {
sum += A->data[i*A->ncols+k]*B->data[k*B->ncols+j];
}
C->data[i*C->ncols+j] = sum;double sum = 0;
for (int k = 0; k < size; k++) {
sum += A[i][k] * B[k][j];
}
C[i][j] = sum;Show Explanation
Row
i, columnkof : First find the address of thei-th row atmat_A->data + i*mat_ncols. Then, increment bykelements to get the address of thek-th element in this row.Row
k, Columnjof : First find the address of thek-th row atmat_B->data + k*mat_B->ncols. Then, increment byielements to get the address of thej-th element in this row.Row
i, Columnjof : First find the address of thei-th row atmat_C->data + i*mat_C->ncols. Then, increment byjelements to get the address of thej-th element in this row.
The row-major order convention is used in C and Python (e.g., NumPy), though column-major order conventions exist in other languages (e.g., FORTRAN). One reasoning is that in C,
A[i][j]almost inevitably implies row-major order because it can be rewritten as(A[i])[j], whereA[i]is a row. Read more on Wikipedia.