1Learning Outcomes¶
Understand that a superscalar processor has CPI < 1.
🎥 Lecture Video
We can try multiple strategies to further increase performance:
Increase clock rate. Limited by technology and power dissipation.
Increase pipeline depth. “Overlap” instruction execution through deeper pipeline, e.g., 10 or 15 stages. Less work per stage means shorter clock cycle/lower power. But there is more potential for all three types of hazards. And more stalling means that our average CPI will be greater than 1.
Design a superscalar processor. Desktops, laptops, cell phones, etc. often have a few of these, combined with simpler 5-stage pipeline processors.
At a high-level, superscalar processors are multiple-issue, meaning they start multiple instructions per clock cycle. In a superscalar processor, multiple execution units execute instructions in parallel, where each execution unit has its own pipeline.
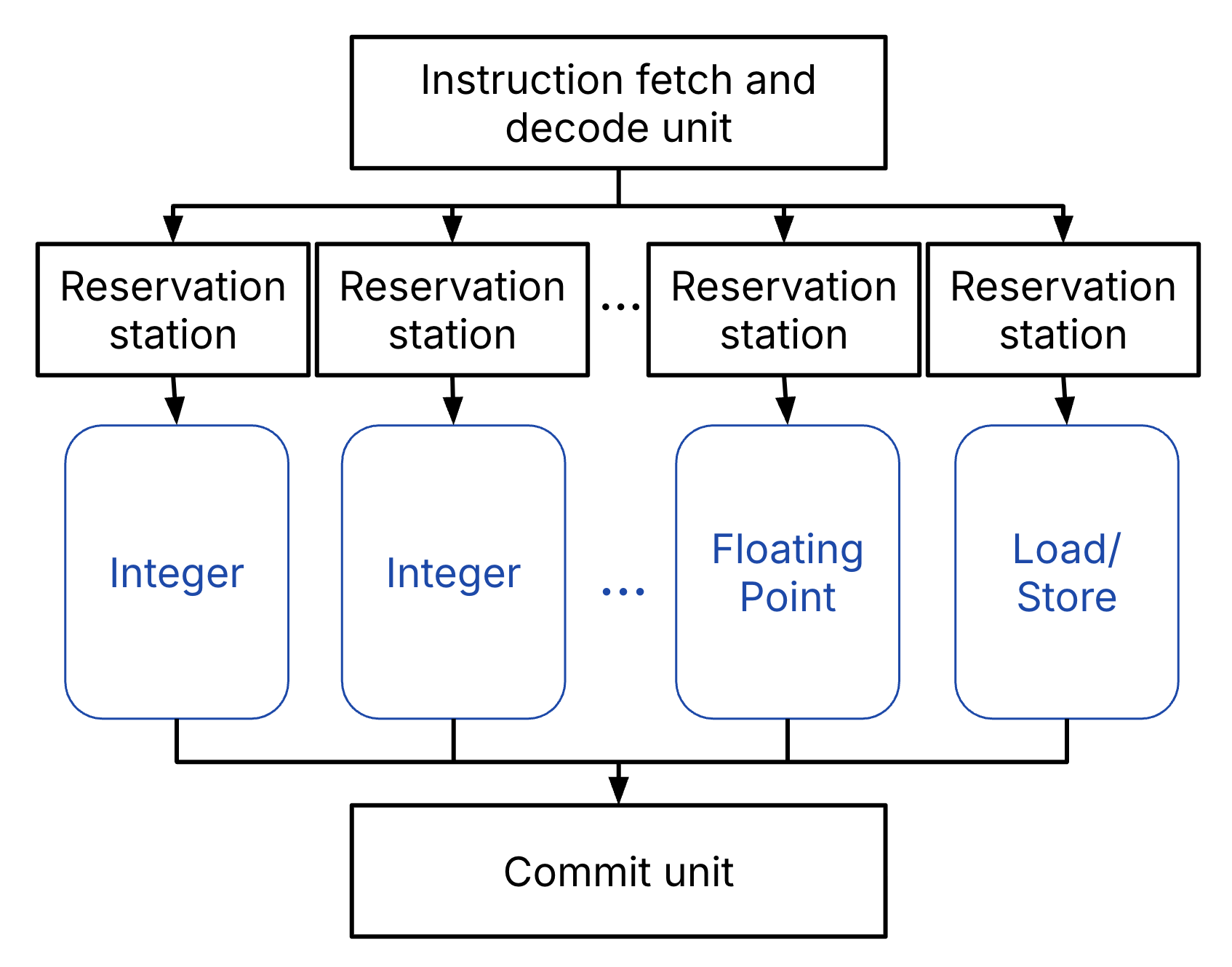
Figure 1:Superscalar processors start multiple instructions per clock cycle.
The processor hardware must also have some sort of dynamic “out-of-order” execution, where it reorders instructions dynamically to reduce impact of hazards.
We note that superscalar processors, where multiple instructions are executed on multiple pipelines in a single processor, should be contrasted with multicore processors, which have separate threads per core.
Superscalar processors start multiple instructions per clock cycle. In our Iron Law of Processor Performance, superscalar processors have average CPI < 1 because IPC > 1 (multiple instructions completed per clock cycle).
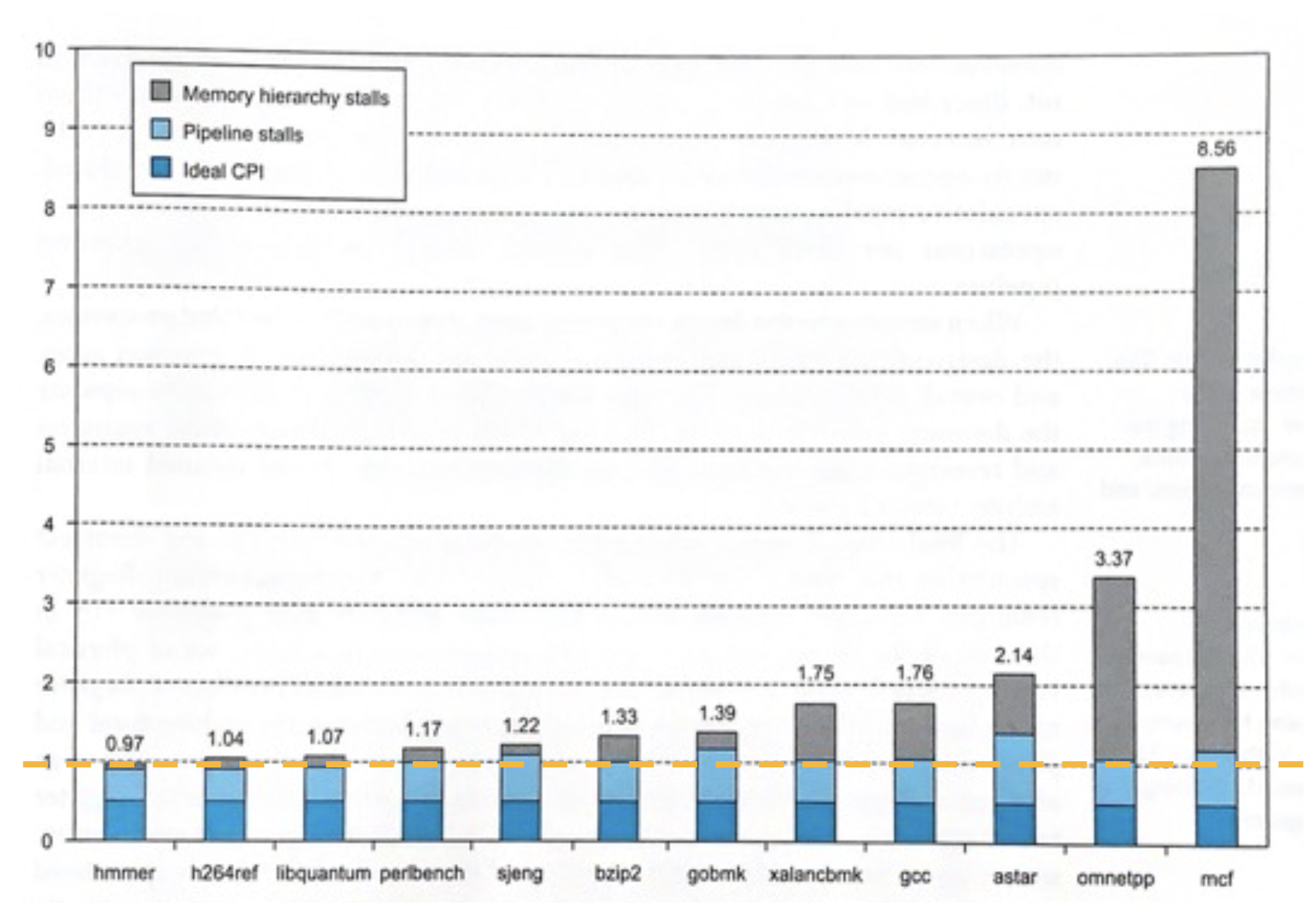
Figure 2:ARM A53 Benchmark (horizontal yellow line where ).