1Learning Outcomes¶
Compare threaded matrix multiplication with sequential programs.
Compare performance using different
gccoptimization flags:-O0,-O2,-O3.
This section is the final and largest step in our incremental performance journey of adapting DGEMM to the underlying hardware of our course hive machines. we use OpenMP to write threaded code that can utilize multiple cores.
Before continuing, we recommend reviewing:
Performance optimizations on a sequential program
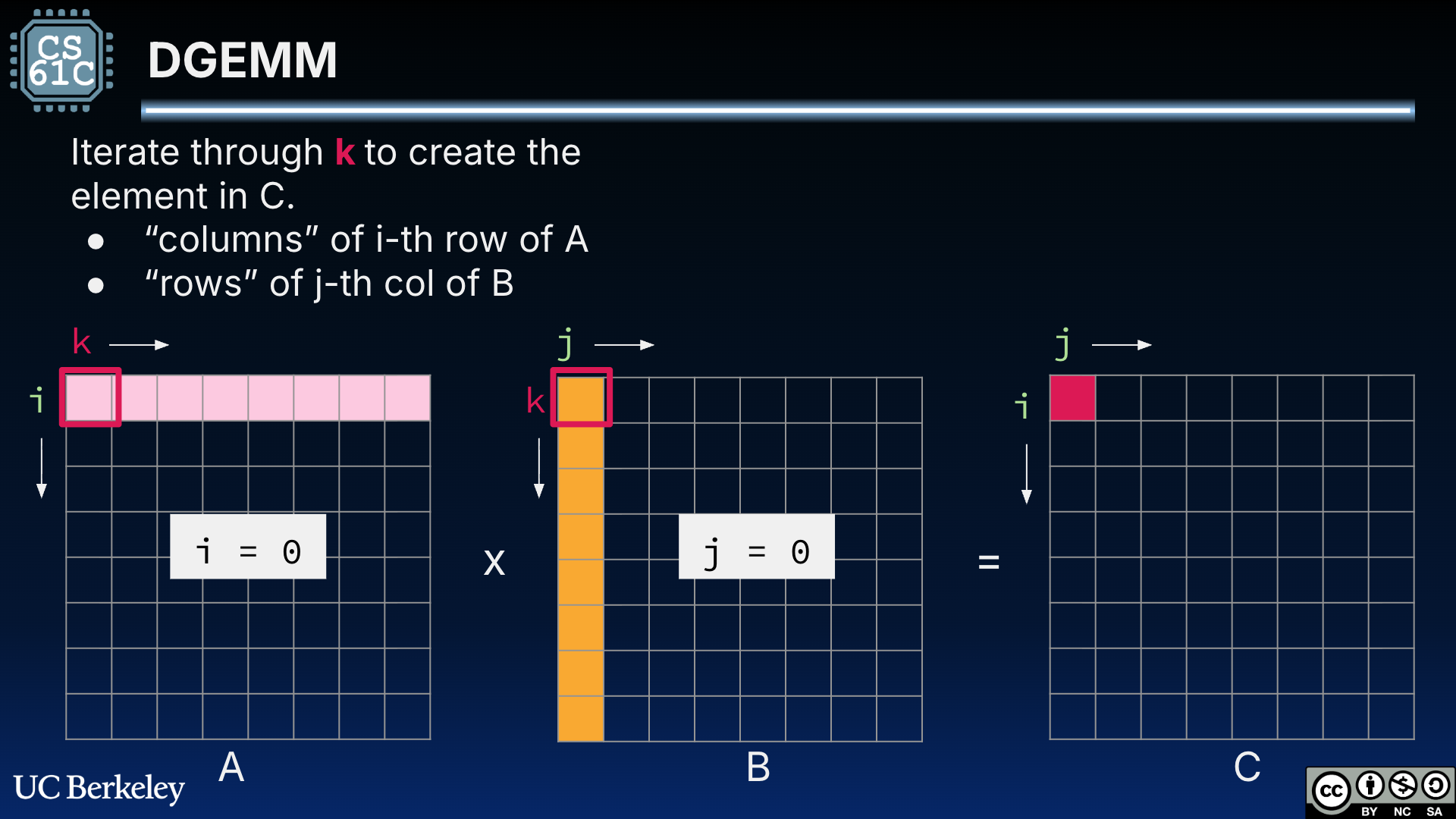
Figure 4:DGEMM for square matrices A and B. is computed as the dot product of row i = 0 of A and column j = 0 of B.
Timing With non-threaded programs, we used the C standard library <time.h> to measure program time. However, on Linux, clock() measures CPU time across all threads, which will lead to an overall over-estimate. In the programs below, we will use omp_get_wtime() to get the wall time from the main thread; this time will be consistent within the main thread but not across threads. Read more on the OpenMP docs..
#include <omp.h>
int main() {
...
clock_t start = omp_get_wtime();
matrix_d_t* C = dgemm(A, B); // threaded
clock_t end = omp_get_wtime();
// execution time in seconds
double delta_time = (double) (end - start)/CLOCKS_PER_SEC;
...
}#include <time.h>
int main() {
...
clock_t start = clock();
matrix_d_t* C = dgemm(A, B);
clock_t end = clock();
// execution time in seconds
double delta_time = (double) (end - start)/CLOCKS_PER_SEC;
...
}2DGEMM 11: OpenMP DGEMM¶
In the below code, line 5 is the single insertion that makes this code run on multiple processors. Line 5, #pragma omp parallel for, is an OpenMP pragma that tells the compiler to use multiple threads in the outermost loop. The resulting compiled program spreads the work of the outermost loop across the 12 threads on the course hive machines. For a 512 x 512 matrix multiplication, each thread then processes about 42 iterations of the loop.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16matrix_d_t *dgemm_openmp(matrix_d_t *A, matrix_d_t *B) { if (A->ncols != B->nrows) return NULL; matrix_d_t *C = init_mat_d(A->nrows, B->ncols); #pragma omp parallel for for (int i = 0; i < A->nrows; i++) { for (int j = 0; j < B->ncols; j++) { double sum = 0; for (int k = 0; k < A->ncols; k++) { sum += A->data[i*A->ncols+k]*B->data[k*B->ncols+j]; } C->data[i*C->ncols+j] = sum; } } return C; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15matrix_d_t *dgemm(matrix_d_t *A, matrix_d_t *B) { if (A->ncols != B->nrows) return NULL; matrix_d_t *C = init_mat_d(A->nrows, B->ncols); for (int i = 0; i < A->nrows; i++) { for (int j = 0; j < B->ncols; j++) { double sum = 0; for (int k = 0; k < A->ncols; k++) { sum += A->data[i*A->ncols+k]*B->data[k*B->ncols+j]; } C->data[i*C->ncols+j] = sum; } } return C; }
Even with no gcc compiler optimizations, our threaded OpenMP DGEMM is now blazingly fast compared to all optimizations we tried earlier and even compared to NumPy:
C 0.768672 seconds
python NumPy: 0.000964 seconds
registers: 0.277462 seconds
simd,naive: 0.416584 seconds
openmp: 0.0000001401 seconds3DGEMM 12: OpenMP Tiled SIMD DGEMM¶
This is our final program optimization. Recall what we said earlier:
The below code combines our core optimizations:
Use Intel Intrinsics to leverage SIMD for floating point operations.
Use cache blocking to tile computation of multiple elements of C simultaneously.
Use OpenMP to spread the outermost loop across all threads.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28static inline void matmul_simd_tile(int si, int sj, int sk, matrix_d_t *A, matrix_d_t *B, matrix_d_t *C) { for (int i = si; i < si + BLOCKSIZE; i++) { for (int j = sj; j < sj + BLOCKSIZE; j+=4) { // 4 doubles at a time avx256_t v_C = avx_load(C->data+i*C->ncols+j); for (int k = sk; k < sk + BLOCKSIZE; k++) { avx256_t s_A = avx_set_num(A->data[(i*A->ncols)+k]); avx256_t v_B = avx_load(B->data+k*B->ncols+j); v_C = avx_mul_add(s_A, v_B, v_C); } avx_store(C->data+i*C->ncols+j, v_C); } } } matrix_d_t *dgemm_openmp_simd_block(matrix_d_t *A, matrix_d_t *B) { if (A->ncols!=B->nrows) return NULL; matrix_d_t *C = init_mat_d(A->nrows, B->ncols); #pragma omp parallel for for (int sj = 0; sj < B->ncols; sj += BLOCKSIZE) { for (int si = 0; si < A->nrows; si += BLOCKSIZE) { for (int sk = 0; sk < A->ncols; sk+= BLOCKSIZE) { matmul_simd_tile(si, sj, sk, A, B, C); } } } return C; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27static inline void matmul_simd_tile(int si, int sj, int sk, matrix_d_t *A, matrix_d_t *B, matrix_d_t *C) { for (int i = si; i < si + BLOCKSIZE; i++) { for (int j = sj; j < sj + BLOCKSIZE; j+=4) { // 4 doubles at a time avx256_t v_C = avx_load(C->data+i*C->ncols+j); for (int k = sk; k < sk + BLOCKSIZE; k++) { avx256_t s_A = avx_set_num(A->data[(i*A->ncols)+k]); avx256_t v_B = avx_load(B->data+k*B->ncols+j); v_C = avx_mul_add(s_A, v_B, v_C); } avx_store(C->data+i*C->ncols+j, v_C); } } } matrix_d_t *dgemm_simd_block(matrix_d_t *A, matrix_d_t *B) { if (A->ncols!=B->nrows) return NULL; matrix_d_t *C = init_mat_d(A->nrows, B->ncols); for (int si = 0; si < A->nrows; si += BLOCKSIZE) { for (int sj = 0; sj < B->ncols; sj += BLOCKSIZE) { for (int sk = 0; sk < A->ncols; sk+= BLOCKSIZE) { matmul_simd_tile(si, sj, sk, A, B, C); } } } return C; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22typedef __m256d avx256_t; // Loads 8 doubles at memory address A into a avx256_t static inline avx256_t avx_load(double *A) { return _mm256_load_pd(A); } // Stores the avx256_t at SRC to DST. Each avx256_t element gets stored in a // different index of the array passed into DST. static inline void avx_store(double *dst, avx256_t src) { _mm256_store_pd(dst, src); } // Creates a avx256_t where every element is equal to num static inline avx256_t avx_set_num(double num) { return _mm256_set1_pd(num); } // A * B + C static inline avx256_t avx_mul_add(avx256_t A, avx256_t B, avx256_t C) { return _mm256_fmadd_pd(A, B, C); }
Combining Intel SIMD Intrinsics and OpenMP gives us our fastest matrix multiplication yet:
C 0.768672 seconds
python NumPy: 0.000964 seconds
registers: 0.277462 seconds
simd,naive: 0.416584 seconds
openmp: 0.0000001401 seconds
openmp,simd,tiled: 0.0000000686 seconds4DGEMM 13: GCC Optimizations¶
Again, let’s compile using different gcc optimization flags in Table 1. The threaded versions win, every time.
Table 1:Threaded DGEMM runtime (in seconds) with different optimization flags.
Program |
|
|
|
|
|---|---|---|---|---|
DGEMM (original) | 0.768672 | 0.197168 | 0.197538 | 0.193889 |
0.416584 | 0.048405 | 0.049970 | 0.049045 | |
0.356344 | 0.033386 | 0.035177 | 0.037030 | |
0.0000001401 | 0.0000000347 | 0.0000000456 | 0.0000000467 | |
0.0000000686 | 0.0000000124 | 0.0000000131 | 0.0000000131 |