1Learning Outcomes¶
Identify the key components of a multicore processor: cores that execute streams of instructions independently but share memory.
Know that in a multicore processor, cores have separate L1/L2 caches but often share an L3 cache.
Give examples of different parallel computing systems, e.g., multicore, datacenter, supercomputer.
🎥 Lecture Video
🎥 Lecture Video
One of the goals of this course is to teach you how to program a computer well enough to increase performance. We recommend reviewing the Iron Law of Processor Performance, which identifies the different components to reducing program execution time:
To improve performance, we could design our architecture as follows:
Increase clock rate, , thereby reducing the time per cycle. If you were a computer engineer building a system, the first thing you might do to increase performance is change the “heart rate” by turning the crank on the clock speed.
For today’s technology, we’ve reached the practical maximum—about 5GHz for general-purpose computers. We have essentially stopped there because of power dissipation and the power wall, i.e., we simply cannot keep these chips cool enough to go much faster. See Figure 1.
Lower CPI, or cycles per instruction. Since we cannot increase the speed at which we complete single instructions, we look at completing multiple instructions in the same cycle. We have briefly discussed instruction-level parallelism[1]; in this unit, we have also introduced SIMD architectures, where one instruction operates on multiple streams of data. SIMD can be seen as one way of completing multiple instructions in one cycle.
Perform multiple tasks simultaneously. Beyond the iron law, we could leverage multiple CPUs to execute related or unrelated tasks (see below).
Do all of the above: High clock frequency, SIMD, and multiple parallel tasks.
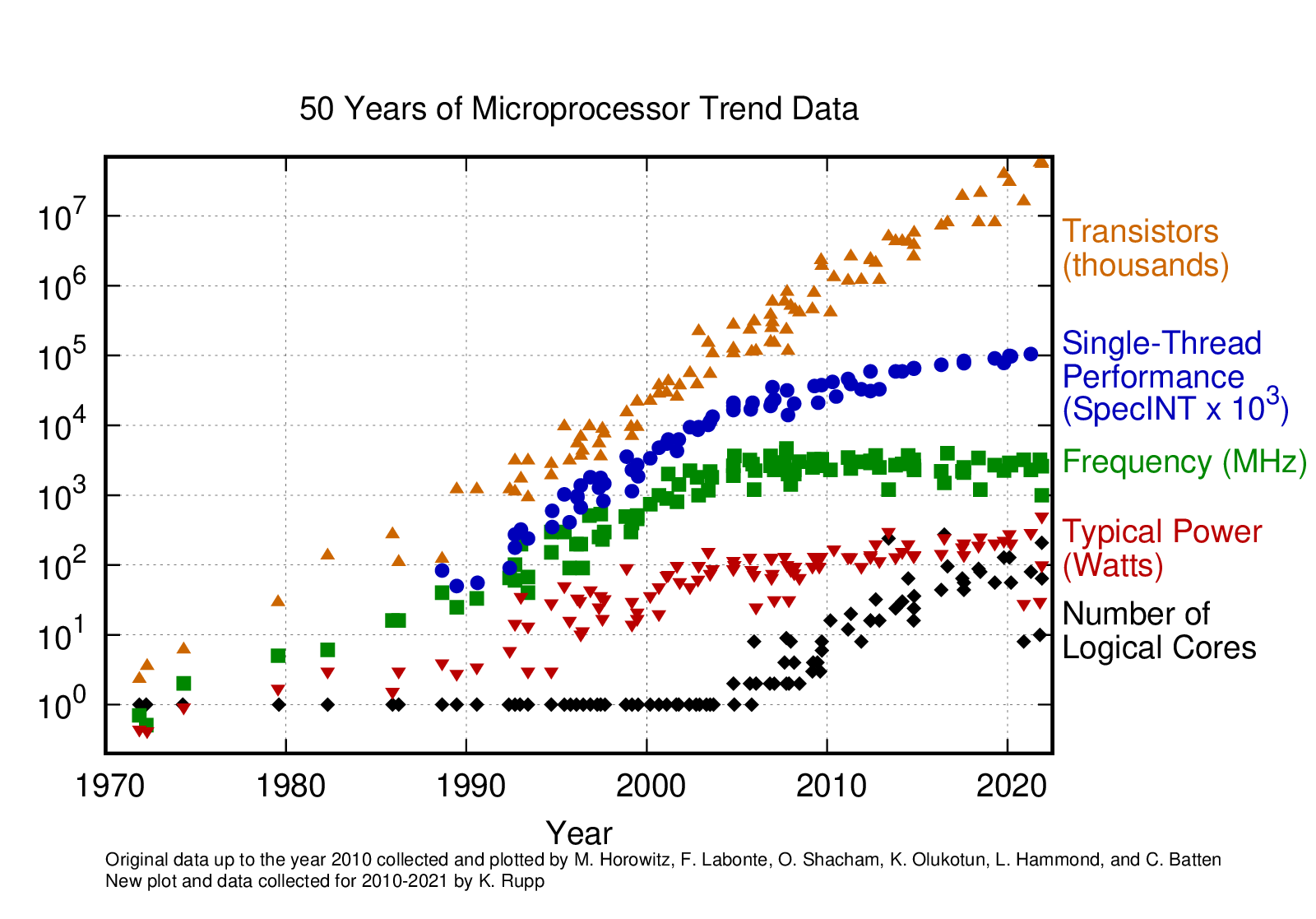
Figure 1:50 Years of Microprocessor Data. Source: Karl Rupp: 42 Years of Microprocessor Trend Data, 2018. GitHub source.
In this section, we discuss how to divide a single program and its data into a parallel space. We introduce two closely related concepts:
(This section) Multicore systems, where a system has multiple processors (i.e., cores) that can run simultaneously; and
(Next section) Multiple threads, i.e., where a program has multiple streams of instructions that can run simultaneously.
Let’s not get ahead of ourselves. Let’s focus just on the hardware for now: multicore.
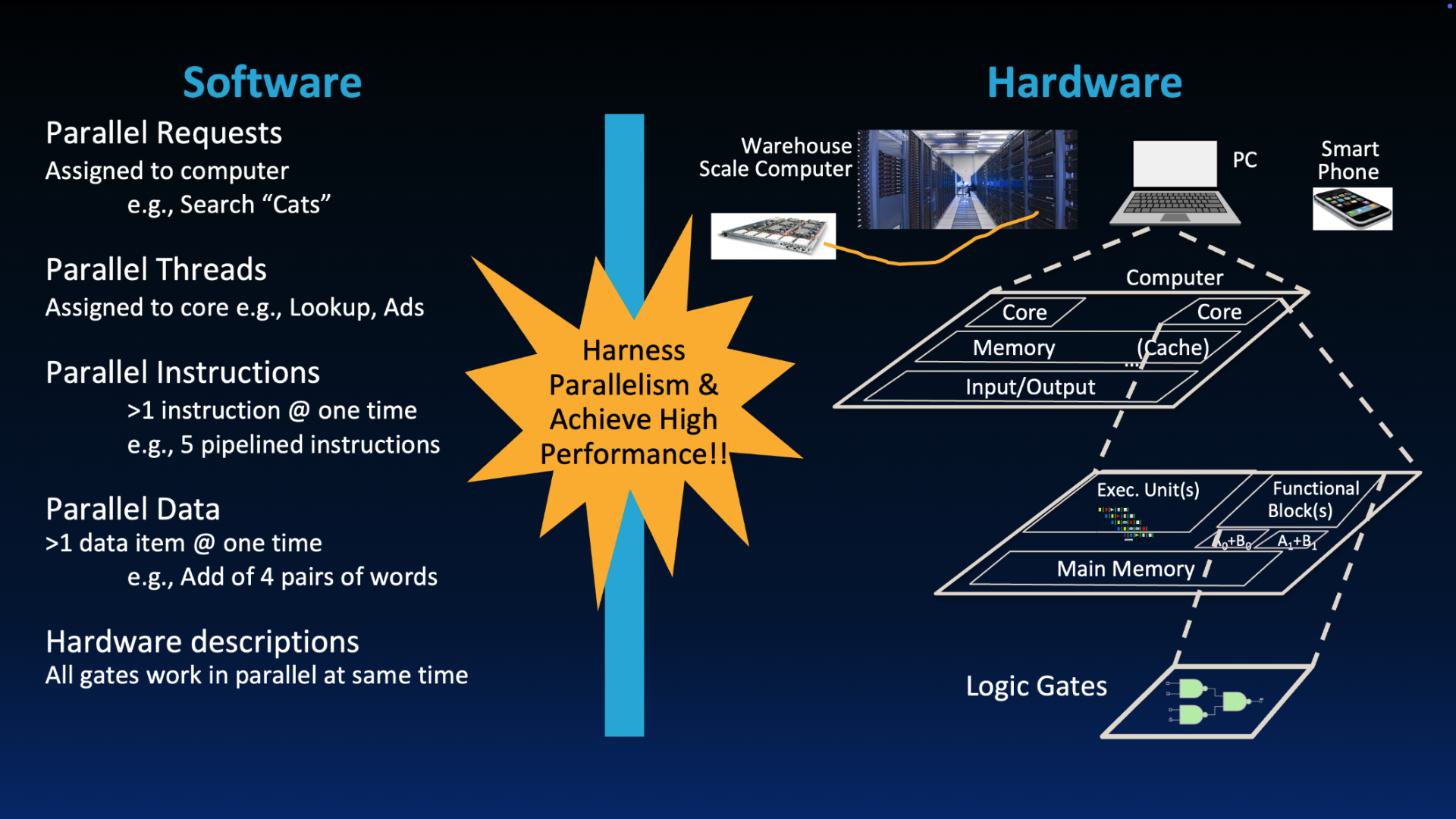
“New-School” Machine Structures leverage parallelism in both software and hardware.
2Multicore Processors¶
In this course, we will focus on multicore machines located in our phones, watches and computers. A multicore processor contains multiple processors (“cores”) in a single integrated circuit. The Apple A14 chip used in iPads and iPhones in the early 2020s is one such multicore system. In the figure below, we see that each core is labeled a CPU (central processing unit).
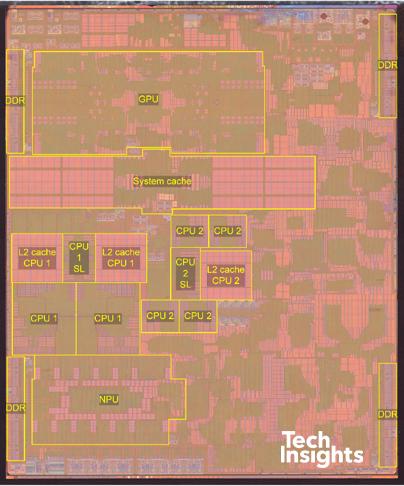
Figure 2:Apple A14 Bionic Chip (sources: Wikipedia, TechInsights)
2.1Multicore processor use cases¶
There are two common uses of a multicore processor:
Partition work of a single task between several cores. For example, each core performs part of a big matrix multiplication. We focus on this application in this course.
Job-level parallelism, where cores work on unrelated problems and there is minimal to no communication between processes running on different cores. For example, HTTP web requests are distributed across different cores, and one core runs Google Slides while another runs Twitch.[2]
2.2Multicore Execution Model¶
There are two components to a multicore execution model (sometimes known as the multiprocessor execution model):
Each processor (core) executes a stream of instructions, or thread, independently from other processors (cores). We discuss threads in a later section.
Each core has its own datapath: PC, registers, ALU, etc.
Each core has its own set of higher-level cahces: L1 and L2 caches.
Shared memory model: All processors (cores) access the same shared memory. We discuss cache coherency in a later section.
All cores share primary memory (DRAM) and sometimes the L3 cache.
Advantages: Processors (cores) can coordinate and communicate by storing to/loading from common locations in shared memory. There can also be just one DRAM unit on the chip.
Disadvantages: Communication between processors must use the slower DRAM medium; recalling our latency analogy, this bottleneck is like “going to Sacramento” on each inter-core communication. Synchronization between cores[3] enforces some serialization of execution, and Amdahl’s Law will eventually be the downfall of any multicore performance gain.
This model is illustrated in Figure 2. Processor 0 and Processor 1 are the two cores in this two-core multicore processor.
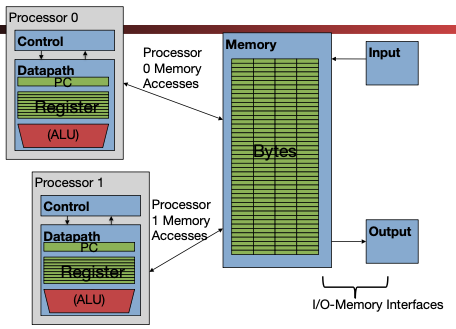
Figure 2:The multicore processor execution model enforces a shared memory model.
Show Explanation of Figure 2
Each core has its own datapath, along with its own control unit, its own program counter, and its own register file. Each core can therefore operate fully autonomously; one can perform an
addwhile the other performs asubinstruction using completely separate registers.The two cores access the same memory (i.e., we do not double the memory hardware requirement).[4] This is the shared memory model.
The two cores also access the same I/O interface.
This chapter explores design of a multicore system:
How many processors (cores) should be supported in this multiprocessor?
Depends on the target workload.
Most systems: Multiple “best available single core within constraints”
Power-critical systems (e.g., phones): “some of the best available single cores” and “some of the most power efficient single cores”, both on the same chip. The Apple M4 chip for 2026 MacBooks is designed this way:[5]
$ sysctl -a | grep "physicalcpu:" hw.perflevel0.physicalcpu: 4 hw.perflevel1.physicalcpu: 6 hw.physicalcpu: 10How do different processors (cores) share data? Via a shared-memory multiprocessor, as discussed above.
How do different processors coordinate/communicate? We will discuss this more when we cover synchronization. At a high-level:
Shared variables in memory and load/store instructions
Coordinated access to shared data through synchronization primitives (e.g., locks) that restrict access to one processor at a time
3More Parallel Computing Systems¶
Parallelism exists at different scales—beyond the multicore systems we discuss in this course.
Historically, parallel computing systems primarily referred to distributed computing systems where multiple machines were wired via Ethernet to work on pieces of a pre-divided job. Nowadays, distributed computing systems refer to supercomputers and datacenters. The former are massive server racks found in national labs and crunch through floating-point data for climate simulations, neural networks and more.[6] The latter are the systems that power our cloud computing frameworks today.

Figure 3:Google Datacenter, in Council Bluffs, Iowa. Google Europe Blog 2012, Data Center Photo Gallery.
To learn more about warehouse-scale computing, check out the bonus lectures in this course.
ILP architectures: Superscalar processors have CPI < 1. Pipelining will not increase CPI but will drastically increase clock speed.
To explore job-level parallelism (also known as process-level parallelism), check out our upper-division Operating Systems course.
Synchronization is when multiple threads of execution (often on different cores)try to coordinate how to read/write to the same spot at the same time. As we will see in a later section, synchronization enforces some serialization of execution.
We did not illustrate caches in Figure 2, but each core would have its own L1 and L2 caches. We discuss virtual memory in a later section.
Read more about Apple’s performance and efficiency cores on Wikipedia and the 2024 Apple press release, “Apple introduces M4 Pro and M4 Max”.
Read about the Savio supercomputer at UC Berkeley.