1Learning Outcomes¶
Develop a working library analogy for memory caches.
🎥 Lecture Video
In this chapter, we focus on the concept of memory and discuss how memory design is critical to computer performance. In the below figure, we focus on two pieces, caches and memory, interact.
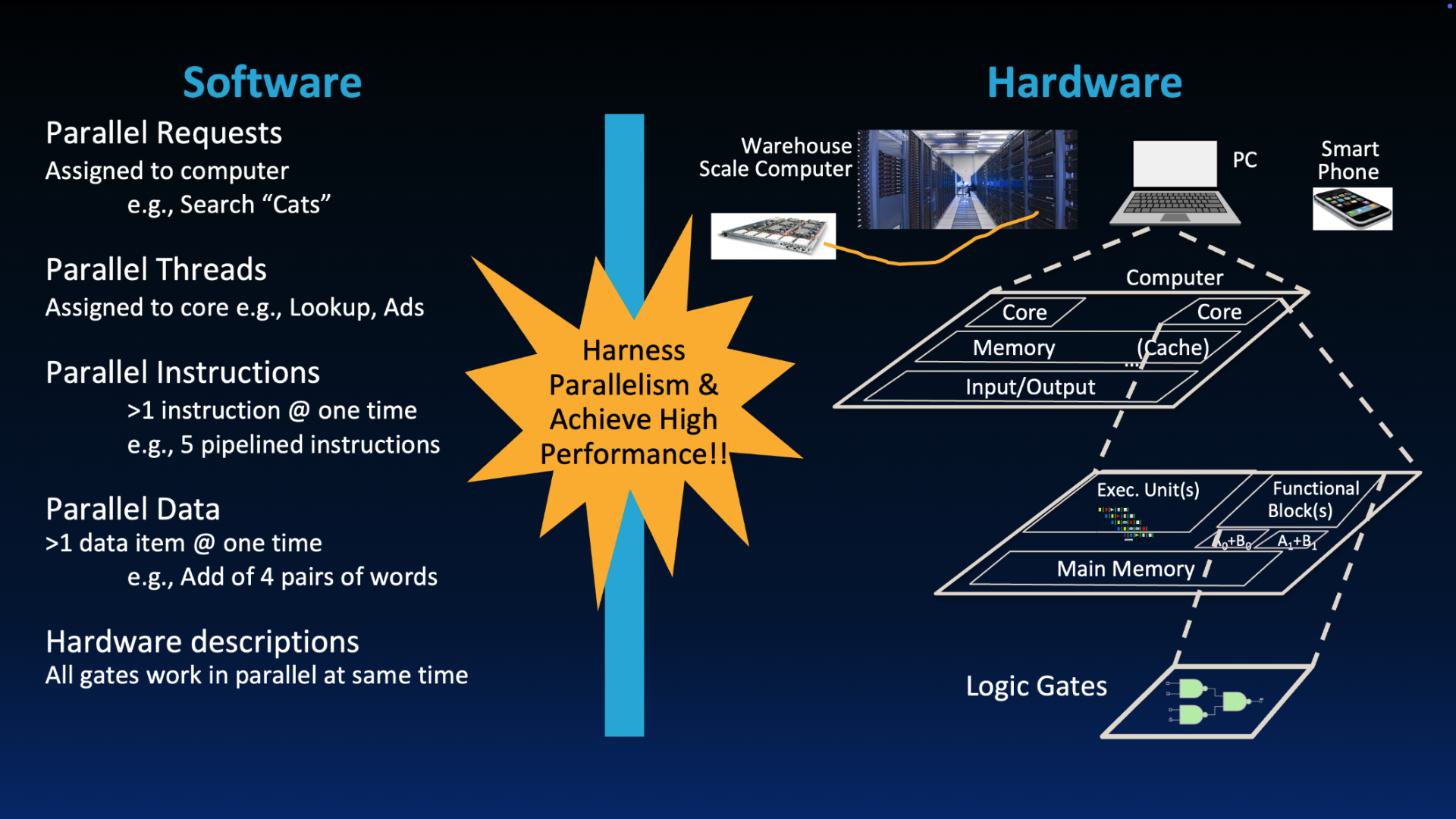
“New-School” Machine Structures leverage parallelism in both software and hardware.
To jog your memory (heh), we revisit our picture of the components of the computer from a way earlier section. We will see in this chapter that the truth is more complex than this picture; we would like to insert caches somewhere. But how?
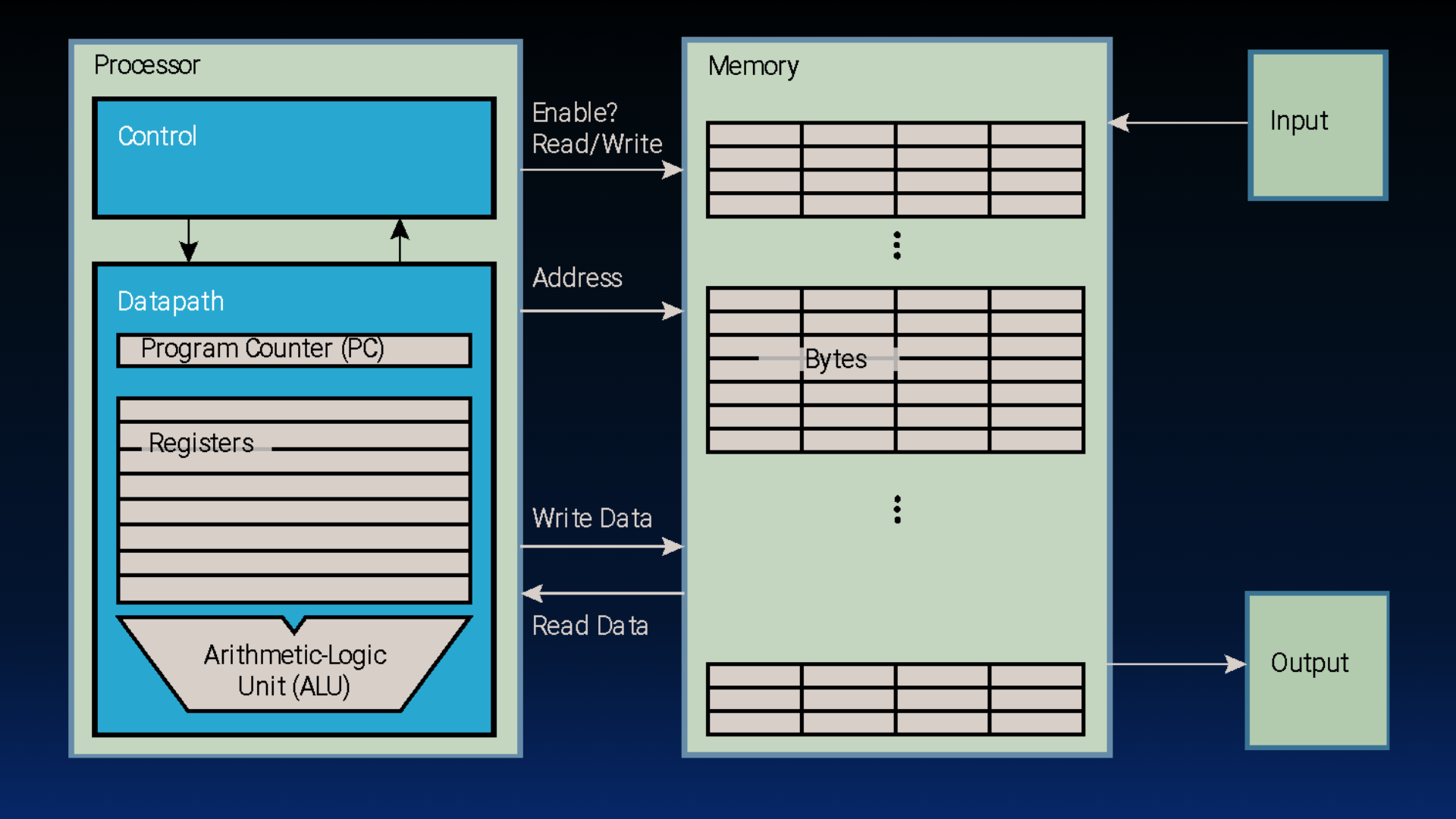
Figure 1:Basic computer layout (See: von Neumann architecture).
2Library: A Memory Analogy¶
To understand caches, it helps to have a good analogy.[1] Let’s review the old-school way to find a book in a big library.
Suppose you are a Cal student and you would like to find a book in the main library, or Main Stacks. There are two stages to your search:
Search a large card catalog. The library catalog[1] is a giant catalog that maps the title/author to the index number (e.g., Dewey Decimal System).
Check out the book. Make a round-trip to walk to Main Stacks, retrieve the desired book, check out the book with the librarian, and walk back to your desk.
2.1Why are large memories slow?¶
Larger libraries worsen both delays: Large libraries will have expansive catalogs, making search longer. Moreover, large libraries physically have more books, so you’ll walk to have farther in your round-trip retrieval.
Just like a library is an expansive “memory” of all books on a campus, electronic memories have the same issue. The delay in memory is compounded by the technology used (e.g., SRAM vs. DRAM vs. disk, discussed in the bonus subsection below).
3Library, continued: A Book Report and a Desk¶
How do you write a report using library books? In practice[2], you would try to minimize your trips down to main stacks as follows:
Search the catalog and look up a book.
Check out the book from Main Stacks (i.e., perform the round-trip walk)
Place book on desk. You find a desk that is in the library, close to Main Stacks.
If you need more, repeat the process and add a new book to your desk. This is the process of locality: don’t return earlier books just yet, since you might need them soon.
Assume there is some limit to the number of books–say, ten books–that you can have open and spread on your table.[3] In the rare case you need an 11th or 12th book, you can go get it, but for the most part, your “working set” of data is very efficient. The time it takes for you to reach a book on your desk is much shorter than the time it would take for you to go to main stacks and read the book. If your desk were smaller (say, like the ones in the HP Auditorium or Wheeler auditorium), you wouldn’t be able to save as many books locally on your desk, and you’d have to take many more trips to Main Stacks.
The critical part of this analogy is your desk that is in the library, close to Main Stacks but not there. The desk is your memory cache: it is a local, fast, and smaller access to the books that you are immediately using. Main Stacks is main memory–it has everything possible, but getting books from there incurs more cost. The collection of ten books on your desk is reasonably sufficient to write most of your report, despite ten books being just 0.00001% of books in Main Stacks (and all of the UC Berkeley libraries).
We know that most libraries have electronic catalogs nowadays, and search is simply some internet search with appropriately mapped keys and tables. Our analogy considers a time before electronic catalogs—card catalogs, where you scroll some giant wheel of cards to look up the location of your book (in linear time).
In practice today, you would also probably not go to the physical library and instead make use of the electronic library resources available. But work with us here. Assume your first step is that you go to the library.
Assume the librarian comes by and says that you can’t stack books, or something.