1Learning Outcomes¶
Understand how Intel Intrinsics exposes the Intel SIMD ISA(s) in the high-level C language.
Write C code that leverages Intel Intrinsics.
Given an Intel intrinsic, interpret register width and (if applicable) packed data type.
🎥 Lecture Video
We have discussed earlier that Intel SIMD instruction set architectures (ISAs) are extensions to the base Intel x86/x87 architecture. ISAs specify assembly instructions. In this section, we discuss at a high-level the assembly instruction format, then focus more on how to call these assembly instructions from our high-level C program using Intel Intrinsics.
2Intel ISA, continued¶
SIMD instructions act as extensions to a base instruction set, with different systems supporting different SIMD instructions.
2.1Intel SIMD Registers¶
The “wide” registers that Intel SIMD architectures use are separate from the general-purpose and floating-point registers used in x86/x87. For example, the SSE2 extension has 128-bit registers. As shown in Figure 1, these 128-bit-wide registers can be interpreted as values packed in different ways: two 64-bit words, four 32-bit words, and so on.
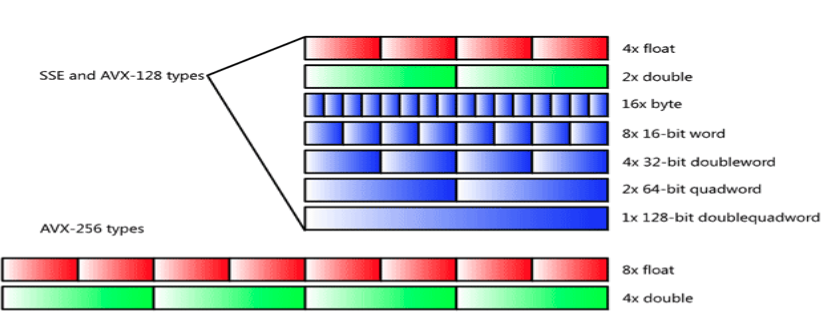
Figure 1:Inte SSE/AVX-128 128-bit-wide registers and AVX 256-bit-wide registers pack different numbers of data types. On Intel architectures, words are 16-bits, so single-precision floating point is a double-word (32bit) and double-precision floating point is a quadword (64-bit).
As a side note, registers from legacy extensions operate on the lower bits of modern extensions, as shown in Figure 2.
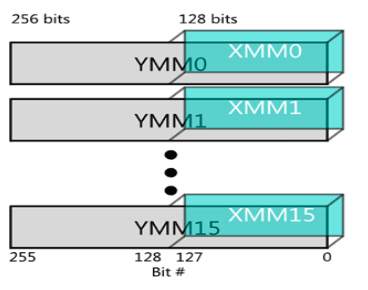
Figure 2:AVX 256-bit-wide YMM registers. Legacy SSE instructions (which use the XMM registers) can still be used to operate on the lower 128 bits of the YMM registers.
2.2Intel SIMD Assembly Instructions¶
Assembly instructions, e.g., in SSE, operate on SSE registers. Expand the below code for examples of SSE extension assembly instructions.
SSE: Adding single-precision floating-point values
Computation to be performed:
// pseudocode
vec_res.x = v1.x + v2.x;
vec_res.y = v1.y + v2.y;
vec_res.z = v1.z + v2.z;
vec_res.w = v1.w + v2.w;SSE Instruction Sequence:
# v1.w | v1.z | v1.y | v1.x -> xmm0
movaps address-of-v1, %xmm0
# v1.w+v2.w | v1.z+v2.z | v1.y+v2.y | v1.x+v2.x -> xmm0
addps address-of-v2, %xmm0
movaps %xmm0, address-of-vec_resWe will not discuss Intel assembly instructions too much in this course. Instead, because we leverage a compiler like gcc to translate C into assembly, we will directly write such instructions into our high-level C programs using Intel intrinsics.
2.3Final comments¶
RISC-V doesn’t have a standard vector library, so we’re using x86’s SIMD extension operators on the course hive machines. In practice, this doesn’t matter too much since arithmetic syntax works similarly to RISC-V.
Some notes:
There’s still only one PC, so we can’t vectorize branch or jump instructions.
Since we only have limited instructions available, we can’t do different math operations to vector components.
The biggest list of SIMD architectures comes from efficient loading and storing (though of course there are small efficiencies from performing arithmetic operations in parallel). However, with SIMD registers we can only easily load/store to/from memory consecutive chunks of memory.[1]
Each instruction needs its own circuitry, so we’re limited to the set of instructions that came with the CPU. Large registers require significant amounts of circuitry, so they are expensive to implement, and often have higher cycles/instruction than standard instructions.
3Intel Intrinsics¶
Intel Intrinsics are C functions and procedures that provide access to assembly language. With intrinsics, we can program using assembly instructions indirectly. There is a one-to-one correspondence between a given Intel intrinsic and an Intel SIMD extension assembly instruction (e.g., SSE, AVX).
3.1Variable Declaration¶
C has typed variables (in contrast to assembly, which only has hardware registers that store bits). To use Intel intrinsics, we must declare registers as C variables of a specific Intel intrisic variable type.
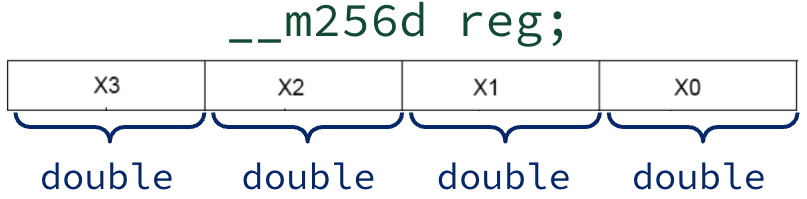
Figure 3:In the Intel AVX family of extensions, registers are 256-bits wide. The corresponding Intel intrinsic __m256d reg; declaration indicates that reg is a 256-bit-wide AVX register that packs four double-precision floating point values.
Table 1:Intel Intrinsic Data Types.
| Type | Intel Intrinsic Family | Description |
|---|---|---|
__m256 | AVX | 256 bit register for storing floats |
__m256d | AVX | 256 bit register for storing doubles |
__m256i | AVX | 256 bit register for storing 32-bit integers |
__m128, __m128d, __m128i | SSE | 128 bit registers |
Once declared, we can use the Intel intrinsic name similarly to C variables. Importantly, the name is associated with available registers, so we can’t just initialize, say, an array of __mm256ds.
3.2Procedures¶
Once we have declared Intel intrisic variables, we can call Intel intrinsics. While these look like functions and procedures, each and every function call maps directly to an assembly instruction for the SIMD hardware.
Table 2:SSE Example: Intel intrinsic mapped to assembly instruction for the SSE SIMD extension. SSE has Intel intrinsic data type _m128 (128-bit-wide register).
| Intel Intrinsic | Assembly Instruction | Comments |
|---|---|---|
_mm_load_ps | movaps | Load/Store operation. Aligned, packed single-precision float |
_mm_store_ps | movaps | Load/Store operation. Aligned, packed single-precision float |
_mm_add_pd | addpd | add packed double |
_mm_mul_pd | mulpd | multiple, packed double |
4Understanding Intel Intrinsics Format¶
Luckily, most intel intrinsic procedures and data types are formatted similarly. Figure 4 provides a guide.

Figure 4:Intel Instructions and Formats.
Show Explanation
In Figure 4, we see that intrinsic signatures follow the form: _mm<register_width>_<instruction>_<datatype>.[2]
__m256i _mm256_add_epi32 (__m256i a, __m256i b); Two 256-bit-wide parameters packed with 32-bit integers, returns one 256-bit-wide result packed with 32-bit integers. From Intel Intrinsics Guide:
Add packed 32-bit integers in a and b, and store the results in dst.
__m128 _mm_load_ps (float const* mem_addr); Parameter is a pointer to a single-precision float. Returns a 128-bit-wide result packed with four floats. From [Intel Intrinsics Guide]:
Load 128-bits (composed of 4 packed single-precision (32-bit) floating-point elements) from memory into dst. mem_addr must be aligned on a 16-byte boundary or a general-protection exception may be generated.
5Example¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24void simd_example_pseudo() { int arr[8] = {3, 1, 4, 1, 5, 9, 2, 6}; // 1. sse128_t sum_sse = sse_set_zero(); // sum_sse: {0, 0, 0, 0} // 2. P sse128_t tmp = sse_load(arr); sum_sse = sse_add(sum_sse, tmp); // sum_sse: {3, 1, 4, 1} // 3. tmp = sse_load(arr + 4); // tmp: {5, 9, 2, 6} sum_sse = sse_add(sum_sse, tmp); // sum_sse: {3 + 5, 1 + 9, 4 + 2, 1 + 6} // sum_sse: {8, 10, 6, 7} // 4. int tmp_arr[4]; sse_store(tmp_arr, sum_sse); int sum = tmp_arr[0] + tmp_arr[1] + tmp_arr[2] + tmp_arr[3]; printf("sum: %d\n", sum); }
Show Answer
Make 4-element subtotal array
sum_sse.Process array
arrelements 0-3 by putting them intosum_sse.Process array
arrelements 4-7 by adding them tosum_sse.Compute the sum of elements in
sum_sse. Do this by storing thesum_ssepacked values into a Cintarraytmp_arr, then summing the values oftmp_arrusing regular C.
Let’s rewrite this pseudocode with Intel Intrinsics, can you explain how the below code implements the vector pseudocode from earlier?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25int simd_example_sse() { int arr[8] = {3, 1, 4, 1, 5, 9, 2, 6}; // 1. __m128i sum_sse = _mm_setzero_si128(); // sum_sse: {0, 0, 0, 0} // 2. __m128i tmp = _mm_loadu_si128((__m128i *) arr); sum_sse = _mm_add_epi32(sum_sse, tmp); // sum_sse: {3, 1, 4, 1} // 3. tmp = _mm_loadu_si128((__m128i *) (arr + 4)); sum_sse = _mm_add_epi32(sum_sse, tmp); // sum_sse: {3 + 5, 1 + 9, 4 + 2, 1 + 6} // 4. int tmp_arr[4]; _mm_storeu_si128((__m128i *) tmp_arr, sum_sse); int sum = tmp_arr[0] + tmp_arr[1] + tmp_arr[2] + tmp_arr[3]; printf("sum: %d\n", sum); return sum; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24void simd_example_pseudo() { int arr[8] = {3, 1, 4, 1, 5, 9, 2, 6}; // 1. sse128_t sum_sse = sse_set_zero(); // sum_sse: {0, 0, 0, 0} // 2. P sse128_t tmp = sse_load(arr); sum_sse = sse_add(sum_sse, tmp); // sum_sse: {3, 1, 4, 1} // 3. tmp = sse_load(arr + 4); // tmp: {5, 9, 2, 6} sum_sse = sse_add(sum_sse, tmp); // sum_sse: {3 + 5, 1 + 9, 4 + 2, 1 + 6} // sum_sse: {8, 10, 6, 7} // 4. int tmp_arr[4]; sse_store(tmp_arr, sum_sse); int sum = tmp_arr[0] + tmp_arr[1] + tmp_arr[2] + tmp_arr[3]; printf("sum: %d\n", sum); }
Table 3 describes some more common operations. Note we use a vector pseudocode here; this is consistent with many final exam examples.
Table 3:Example SIMD Operations with Intel Intrinsics
| SIMD Pseudocode | Intel Intrinsic (SSE or AVX) | Description |
|---|---|---|
vector vec_load(int31_t *A); | __m128i _mm_loadu_si128(__m128i *p) | Loads four integers at memory address A into a vector. |
void vec_store(int32_t *dst, vector src); | void _mm_storeu_si128(__m128i *p, __m128i a) | Stores src to dst. |
vector vec_setnum(int32_t num); | n/a | Creates a vector where every element is equal to num. |
vec_setnum(0); | __m128i _mm_setzero_si128() | Creates a vector with all elements set to zero. |
vec_setnum(*p); | __m256d _mm256_broadcast_sd(double const *p) | Creates a vector with all elements set to double (from memory). |
vector vec_add(vector A, vector B); | __m128i _mm_add_epi32(__m128i a, __m128i b) | Returns the result of adding A and B element-wise. |
6Common mistakes with SIMD instructions¶
Trying to directly access a 32-bit chunk of a SIMD register (such as through typecasting)
Need to do an explicit load/store, since registers are different from memory
Trying to
_mm_loador_mm_storewith unaligned addressesUse
loaduorstoreuif you must, or try to get your addresses aligned.For
mallocs,aligned_alloc(from C<stdlib.h>, C11 or later) gives you an aligned address.
Forgetting the “tail” case
If your data isn’t an array whose length is a multiple of your SIMD register size (e.g., 4), you need to handle the last iterations of your dataset one-by-one instead of, e.g., 4 at a time.
Using too many SIMD registers (or creating a large array of registers)
Ends up throttling your code because the compiler ends up trying load/store SIMD registers to the stack a bunch of times.
Again, vector architectures are not SIMD architectures, even though SIMD architectures implement some vector operations. Again, one big difference is that SIMD operations are limited to consecutive memory access, whereas vector architecture operations are not.
The
pinepi32andpsstands for “packed.” Theeinepi32likely stands for “extended” (e.g., from MMX to SSE), and thesinsi64likely stands for “scalar.” Stack Overflow